SFTP Bulk
Adding SFTP Bulk as data source
The following connector information is required from the client:
-
Username
-
Password
-
Host
-
Port
-
File Type
-
Stream Name
-
Folder Path
-
CSV Separator
-
Start Date
Do the following:
-
Login to a SFTP server using your credentials.
-
Create a folder in the server and drop your files there.
To add SFTP Bulk as data source, do the following:
-
From the left navigation panel, click Lakehouse and then click Data Sources.
-
From the upper right corner of the page, click the + New Data Source button to start the process of adding a new database.
-
In the New Data Source page, click the SFTP icon.
-
Specify the following details to add SFTP Bulk. Once you have connected a data source, the system immediately fetches its schema. After this schema retrieval process is complete you can browse and interact with the tables and data.
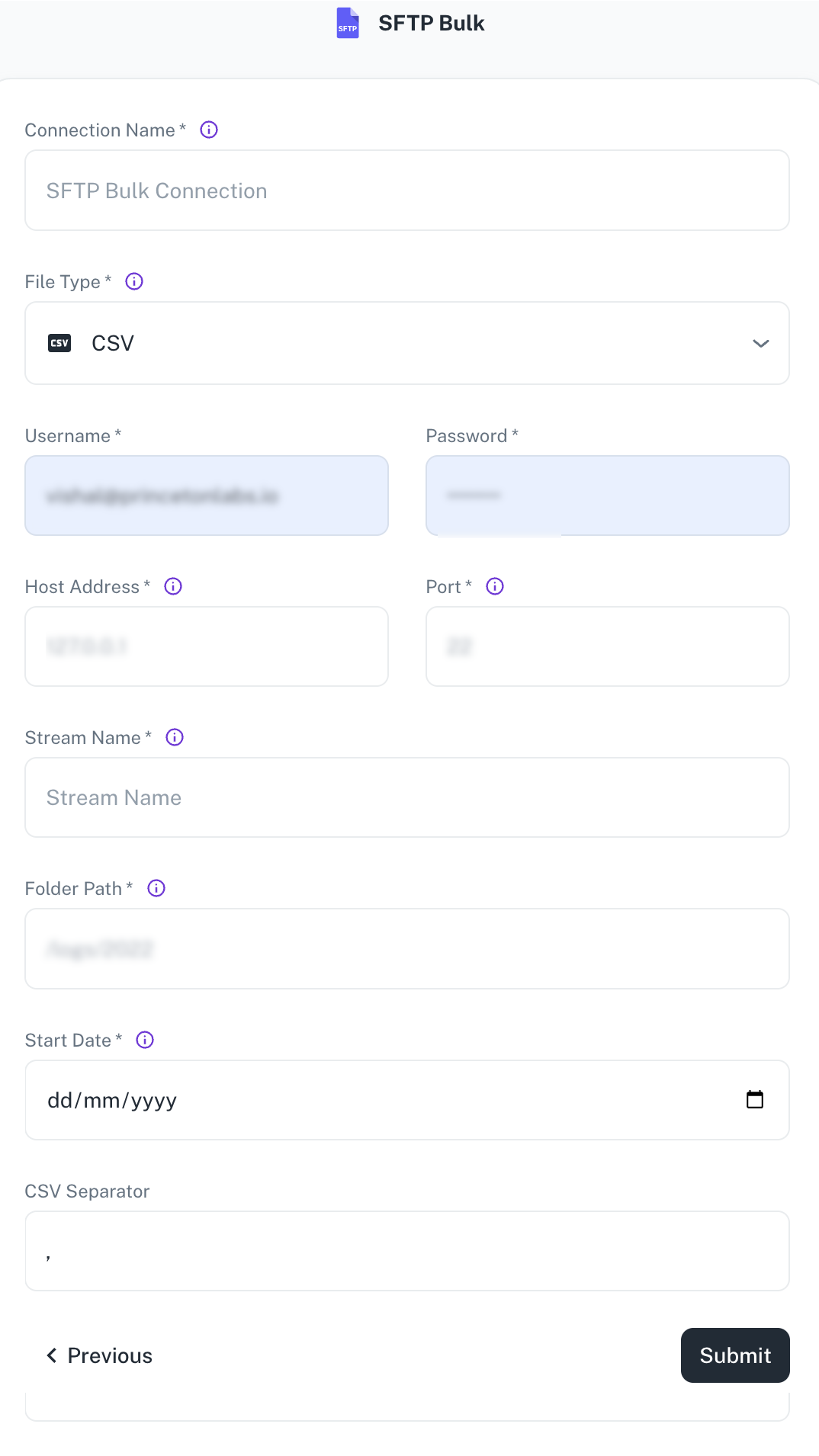
Field Description Connection Name Enter a unique name for the connection. File Type Currently, only CSV files are supported. Username / Password Specify the client credentials. Host Address Specify the SFTP server address. Port Specify the port number of the SFTP server. Stream Name Enter name of the output table you want to create. Specify the desired name for the data stream (table) in the destination warehouse. This can be any name and is independent of the actual CSV file names. Sync modes (incremental/full refresh) are configured at the stream level, not at the pipeline level. Folder Path Provide the absolute path to the folder on the SFTP server containing the CSV files (e.g., /home/Ubuntu/SFTP/credit). Ensure this path is accurate.Start Date Specify the date from which to begin replicating data. This allows for historical data selection. CSV separator Specify the delimiter used in the CSV files (comma is the default). Other separators like spaces can also be configured. -
Click Submit.
Supported Sync modes
- Full Refresh | Overwrite
- Full Refresh | Append
- Sync Incremental | Append
Supported Streams
This source provides a single stream per file with a dynamic schema. The current supported type files are Avro, CSV, JSONL, Parquet, and Document File Type Format.
Was this helpful?